Abstract
Learning a latent dynamics model provides a task-agnostic representation of an agent's understanding of its environment. Leveraging this knowledge for model-based reinforcement learning holds the potential to improve sample efficiency over model-free methods by learning from imagined rollouts. Furthermore, because the latent space serves as input to behavior models, the informative representations learned by the world model facilitate efficient learning of desired skills. Most existing methods rely on holistic representations of the environment’s state. In contrast, humans reason about objects and their interactions, predicting how actions will affect specific parts of their surroundings. Inspired by this, we propose Slot-Attention for Object-centric Latent Dynamics (SOLD), a novel model-based RL algorithm that learns object-centric dynamics models in an unsupervised manner from pixel inputs. We demonstrate that the structured latent space not only improves model interpretability but also provides a valuable input space for behavior models to reason over. Our results show that SOLD outperforms DreamerV3 and TD-MPC2 — state-of-the-art model-based RL algorithms — across a range of benchmark robotic environments that require relational reasoning and manipulation capabilities.
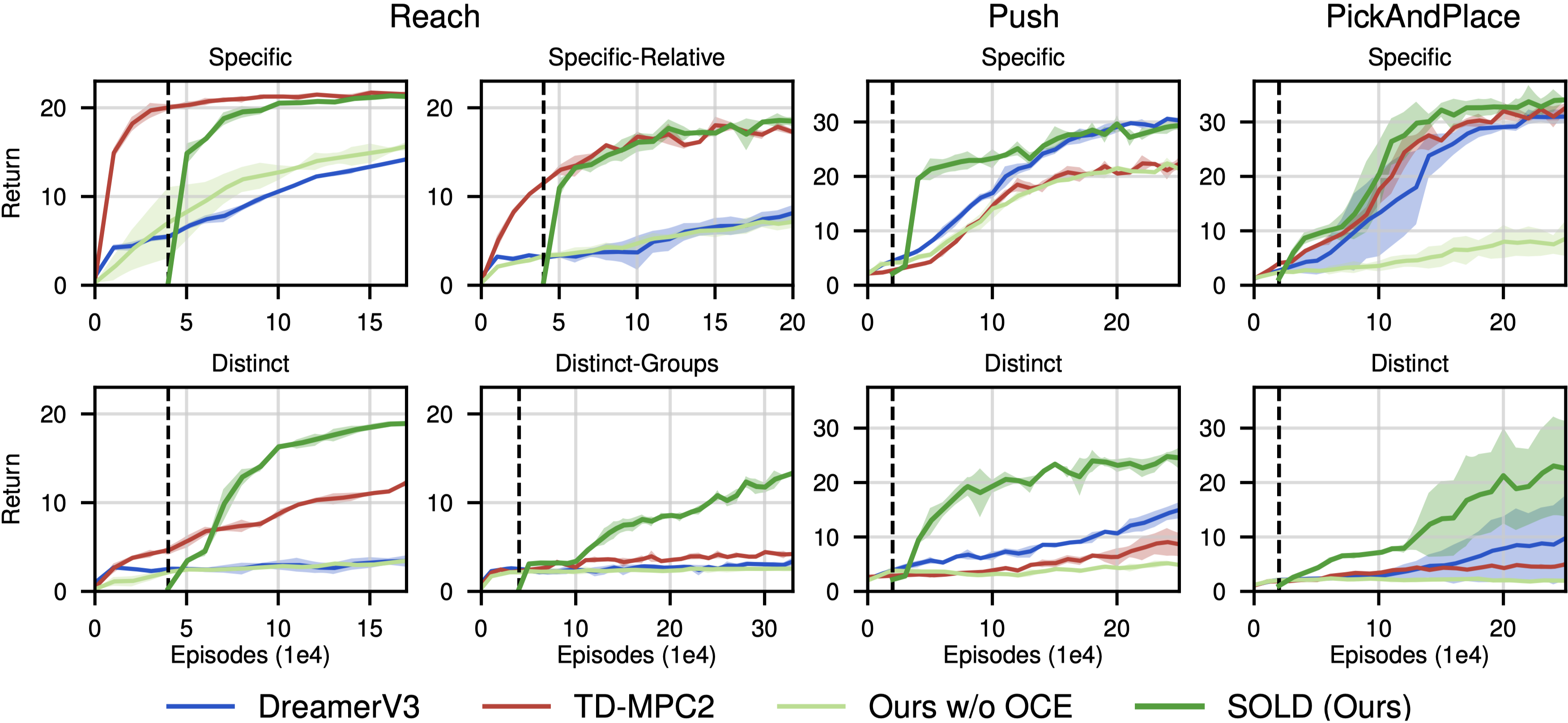
Reach-Specific
Reach-Specific-Relative
Push-Specific
Pick-Specific
Reach-Distinct
Reach-Distinct-Groups
Push-Distinct
Pick-Distinct
SOLD compares favorably to existing state-of-the-art model-based RL methods on the introduced benchmark, which extends visual robotic control tasks by requiring relational reasoning to solve problems.
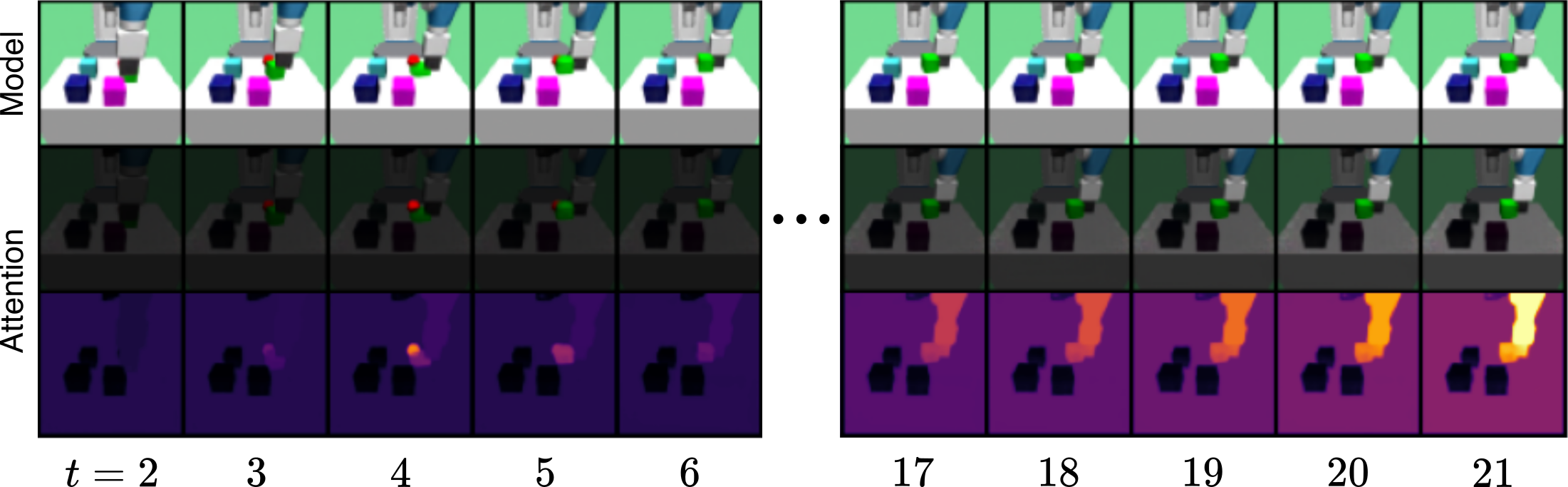
The learned object-centric latent dynamics model is showcased through open-loop predictions in the videos below. These predictions remain accurate over long horizons, consistently maintaining the object-centric decomposition of the environment. We can see how SOLD predicts individual scene elements to evolve over time under a given action sequence.indicates ground-truth frames, whilerepresents open-loop predictions.
Button-Press
Hammer
Finger-Spin
Cartpole-Balance
SOLD autonomously identifies task-relevant objects over long horizons, producing interpretable attention patterns in the behavior models. In the Push-Specific task shown below, the actor model consistently focuses on the robot and the green target cube while disregarding distractors. Notably, it attends to the occluded red sphere in a distant past frame to retrieve the goal position and infer that the green cube is correctly placed.
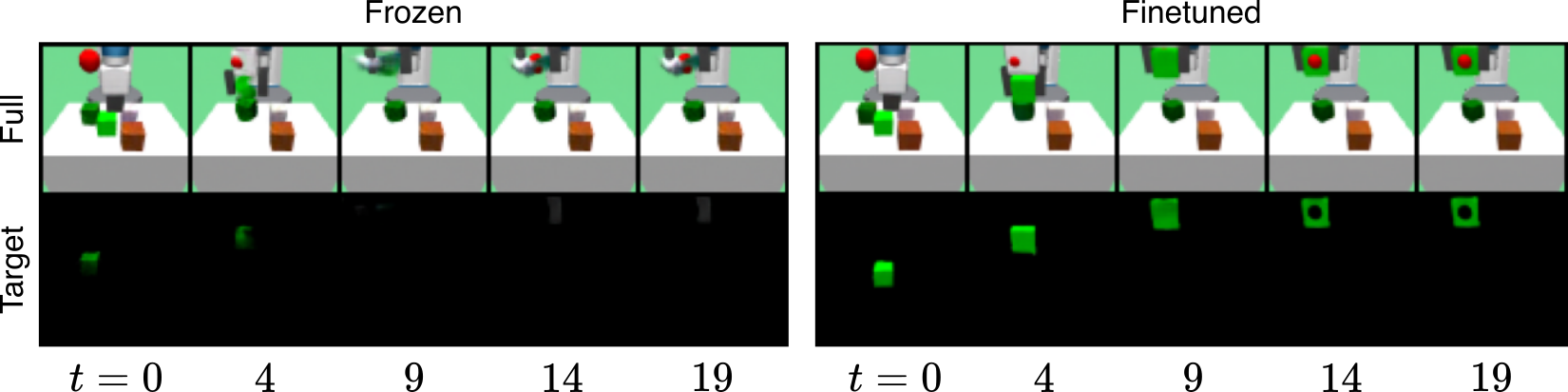
Pretraining an object-centric encoder-decoder on random sequences and freezing it during RL training is a common limitation of prior methods. This approach limits applicability to tasks where the state distributions induced by learned policies are similar to those encountered under random behavior. In Pick tasks, this assumption is violated, as random behavior rarely results in grasping and lifting a block. We demonstrate that finetuning the object-centric encoder-decoder is essential in these cases and remains stable during RL training. The figure below shows full reconstructions and target cube reconstructions for both frozen and finetuned SAVi models.
In addition to the studied RL environments, we further demonstrate the ability of our object-centric dynamics model to handle realistic observations and complex action spaces. To this end, we train on the Sketchy dataset, which provides real-world visual observations and 7-dimensional robotic arm actions. Our results show that SOLD successfully learns meaningful object decompositions and accurately models the underlying dynamics.
The Moving Shapes dataset below, requires the model to associate actions with the object to which they apply. By learning these associations, our model is able to accurately predict the scene dynamics, enabling it to generalize to settings where actions may simultaneously affect multiple objects within a scene.
Loading...